



In the previous article, by unleashing Lerna and Yarn workspaces' power, we have successfully migrated a few autonomous projects into a single repository. Well done, we. Time to adjust the existing processes and pipelines to ensure they all still run flawlessly without any unexpected downtime.
Workflows requirements
There is one thing that must be clarified before getting right into the workflows' description. The solutions presented below will not match every single use case that you may have to deal with. They cannot be treated as one-serves-all recipes; it all may vary depending on the initial assumptions about the goals you are trying to achieve and processes that you are trying to simplify with the migration to monorepo. I will try to underline what parts of the workflows can be solved in another way given the different requirements you need to meet, but in general, the approach described below is tailor-made to keep our existing frontend pipelines almost untouched.
That being said, let me list all the objectives that we need to keep in mind during the workflows design phase:
- keeping projects private;
- independent releases (deployments);
- integration with external deployments orchestrator via GitHub webhooks;
- independent merge-blocking tests execution;
- access to the shared subprojects from outside of the monorepo.
While the common and already well-described scenarios for the monorepo end with accessible packages publishing (via lerna publish), most of our subprojects are not meant to fit into package definition; they should be rather characterized as separate web applications.
Dependency outjection
Our existing approach to continuous deployment cannot be simpler. Multiple "release" pipelines are now linked to a separate GitHub repository each and triggered by webhooks on successful merges to master. Then, the build stage kicks off - Docker images stored in each repo are used to set up the build environment and execute specific scripts to produce the final bundle and make sure that the output is put on a proper server end users have access to. Nothing that falls under the black magic term, really. As you can probably imagine, there must be yarn install command executed somewhere within this process. That is totally intuitive and reasonable - we need to somehow fetch the external resources (listed in package.json and associated with specific versions described in yarn.lock) that the project depends on.
Sure, from now onwards, both build and deployment pipelines will be linked to a single repository so if you think that all the build scripts will need to be modified to make sure we are executing them from a specific subdirectory (/packages/<deployed_project>), you are right. If you also think that except this small addition we should be fine with leaving the rest of the build steps unchanged... Well, I must disappoint you. You are wrong.
Okay, I will not be that mean. You are not entirely wrong, but if you decide to stick to classic yarn install after navigating to a proper directory containing the project the pipeline is focused on, without complex caching the workflow will quickly become extremely inefficient. I am not that mean, but it still sounds serious. Why?
Focused installations with Yarn workspaces
First things first. Wherever you execute yarn install from the scope of the project built on top of workspaces, all the dependencies for all of the workspaces will be installed. Obviously, if we develop the project locally, we do not run this command frequently (a pretty cool euphemism for "we only run this command once each time the dependencies list is updated" by the way!). Continuous deployment environments are usually stateless (clean), so with PnP mode disabled even with lockfile's hash-based caching all the dependencies will be downloaded pretty often. Given that this step is generally one of the major bottlenecks for the whole build stage, it is pretty clear that - in terms of a bundling time - we can benefit a lot from optimizing it. To be fair - it will not hit you that much when the monorepo you work with contains just a few projects with many shared dependencies; in other cases - you will start to suffer sooner or later.
Fortunately, Yarn authors had also paid attention to the ability to install only the dependencies needed by a single workspace. At least they made us think that they did. The resolution of a single workspace's dependencies boils down to a focused installation term in Yarn's nomenclature. After inspecting this package manager's documentation, we can quickly notice that --focus flag seems to do exactly what we are looking for.
But there is a noticeable difference between seems to do and does here.
While the more detailed documentation about focused installations still makes us believe that the holy grail is there in front of us, if only we try to use the --focus flag for the first time, it quickly turns out to be a well-masked Pandora's box. The documentation claims that instead of building the subprojects that the workspace we are focused on depends on, Yarn will try to fetch the corresponding package from the packages registry. This is completely fine - if we are not going to touch other workspaces, the pre-built equivalent must be accessed in any other way, and the fallback to the packages registry sounds reasonable. Shared subprojects still need to be accessible by the projects outside of the monorepo (see point 6. in requirements section), so we will eventually have to publish it somewhere and packages registry fits into the definition of somewhere. The problem is that Yarn's focused installation not only tries to access the already published package containing shared dependency - it also attempts to fetch pre-published packages for the subprojects that are not referenced by the workspace we are trying to run yarn install --focus for.
$ # remember that repo_a references shared_lib only
$ cd packages/repo_a/
$ yarn install --focus
yarn install v1.22.4
[1/4] Resolving packages...
error Couldn't find package "@tripleequalsdev/repo_b@1.0.0" required by "workspace-aggregator-5d7a7693-4b17-4bdb-9db5-75e1fab1fccb@1.0.0" on the "npm" registry.Instead of traversing the dependencies graph for the specific project we are trying to build to correctly identify what needs to be installed from an external origin, it forces us to have all the packages for all of the workspaces already published. When we do not intend to create packages out of some of our workspaces (what is a valid statement for our case), we are screwed. If you do not believe me, ask these folks.
Friendship with Yarn ended?
Younger brother to the rescue
I am not going to tell you that I was not disappointed when I read that Yarn authors are not willing to fix that little limitation in most widely used version 1 due to the nature of modules hoisting. The fact that the issue were moved under Yarn 2 scope gave me some hope.
I know that the second version of the beloved package manager was announced as stable a few months ago, but I have been hesitant to try it out in an already large and reliable commercial ecosystem based on broadly adopted Yarn 1. On the other hand, I have been curious and eager to compare their performance, play with PnP, and prove that the migration from version 1.x goes really as flawlessly as the authors had been claiming. Now, when I am left with no choice...
Migration to Yarn 2
The migration guide is pretty clear. Let's navigate to the root directory of our monorepo and execute all the required steps.
Step 1. Yarn 2 (codenamed berry) installation:
$ yarn set version berry
Resolving berry to a url...
Downloading https://github.com/yarnpkg/berry/raw/master/packages/berry-cli/bin/berry.js...
Saving it into D:\projects\monorepo\.yarn\releases\yarn-berry.js...
Updating D:\projects\monorepo\.yarnrc.yml...
Done!Step 2. For the first iteration we do not want to consume zero-installs mode, so we need to add the following to our .gitignore:
+ .yarn/*
+ !.yarn/releases
+ !.yarn/plugins
+ !.yarn/sdks
+ !.yarn/versions
+ .pnp.*Step 3. (optional) Given that I currently have zero experience with PnP enabled, I decided to set up the fallback to classic approach with node-modules. There should not be any difference, but let's stick to what we are used to - we can always enable PnP in the future. PnP mode is enabled by default, so to change the way the dependencies are linked, we need to add the following line to .yarnrc.yml (the file storing per-project Yarn configuration):
yarnPath: ".yarn/releases/yarn-berry.js"
+ nodeLinker: "node-modules"Step 4. Installation of the plugin to enhance the workspaces support:
$ yarn plugin import workspace-tools
➤ YN0000: Downloading https://github.com/yarnpkg/berry/raw/master/packages/plugin-workspace-tools/bin/%40yarnpkg/plugin-workspace-tools.js
➤ YN0000: Saving the new plugin in .yarn/plugins/@yarnpkg/plugin-workspace-tools.cjs
➤ YN0000: Done in 1.37sStep 5. Lockfile regeneration to match the new layout expected by Yarn 2:
$ yarn install
➤ YN0065: Yarn will periodically gather anonymous telemetry: https://yarnpkg.com/advanced/telemetry
➤ YN0065: Run yarn config set --home enableTelemetry 0 to disable
➤ YN0000: ┌ Resolution step
...
➤ YN0000: Done with warnings in 5.2mStep 6. Trying brand new focused installation™:
$ cd packages/repo_a/
$ yarn workspaces focus
➤ YN0000: ┌ Resolution step
...
➤ YN0000: Done with warnings in 36.46sContinuous deployment workflow
Although we are keeping the regular development experience untouched (we can still follow the exact same paths when we develop new features locally), in order to be efficient, the deployment workflow needs to match the following flowchart (assuming that there is a pending repo_a update):
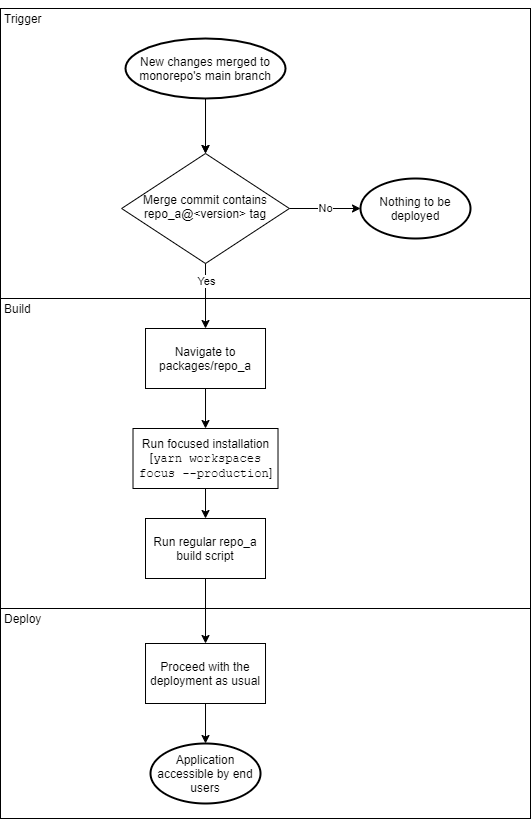
As mentioned in one of the previous chapters, the only updates required should be applied in the trigger and build flows. The rest of the process remains unchanged, so the major deployment phase that has already been working well in the pre-monorepo era is unaffected.
Tying everything together with the new CI process
Remember the short paragraph about independent versioning from the previous article? Now it is time to fully unleash Lerna's power to set up a new continuous integration workflow fully compliant with our initial requirements.
Independent tests' runs
Whenever you apply a fully isolated change to any subprojects within the monorepo, running all test suites for all monorepo ingredients is too much. It makes the whole test execution phase more time-consuming without any real benefits. By definition, tests should be deterministic, so if you do not touch a completely independent subproject, the result of its tests will not vary from the very last outcome.
Thanks to Lerna, we do not have to manage what and when to run ourselves. It determines what projects are affected by our changes based on the commits' history and the contents of the branch we are trying to introduce to the main codebase; what is even cooler, it provides us a mechanism to run aggregated NPM scripts for those as well. The spell we all need (and deserve!) is really simple: lerna run <script_name> --since --. There are three things though that you need to be aware of before casting it:
- it needs to be run from the root directory;
- when the script is not defined in any of the projects'
package.json, it will not fail - it will still execute the command for the packages that have it present; --since --option tells Lerna to execute everything for the projects that have been affected by all the changes since the latest commit tag, so when you want to run that command locally, please make sure your branch is up-to-date withmaster(either mergemasterinto it first or do the rebase).
Since we use the usual GitHub PR process to integrate the changes into the main branch, it makes sense to execute the tests inside the same ecosystem - that is why I decided to put that workflow in the GitHub action. The simplified (with some insignificant bits cut off) workflow configuration file is listed below:
name: Tests execution workflow
on:
pull_request:
branches:
- master
jobs:
test:
name: Execute test suites for all affected projects
runs-on: ubuntu-latest
env:
node-version: 14.x
steps:
- uses: actions/checkout@v2
with:
fetch-depth: "0" # Lerna needs full commit history (including existing tags)
- name: Use Node.js ${{ env.node-version }}
uses: actions/setup-node@v1
with:
node-version: ${{ env.node-version }}
- name: Install dependencies
run: yarn install --immutable
- name: Run tests
run: yarn dlx lerna run test --since -- # no "global add" in Yarn 2Generating tags to kick off CD pipelines
Assuming that you have read what will trigger the continuous deployment workflow, you are probably wondering how we are going to generate commit tags automatically. It is pretty obvious that if we decided to create them manually, at some point we would encounter some nasty and not easy to resolve tags conflicts. That is why this step is also driven by our CI, and must not be executed manually.
When do we want to generate new tags to kick off CD? The answer is easy - whenever we are confident enough that the change should be integrated with the main branch (in other words: whenever the pull request is merged into master). GitHub actions allow us to detect if such integration has been completed and trigger the custom workflow then.
How are we going to determine what projects should have their versions bumped? That is when Lerna shines brightly again. While this is also possible with Yarn 2 (yarn version check), Lerna not only lists the names of the subprojects that have been affected by our changes since the last tag with their new corresponding versions; it also prepares the relevant package.jsons modifications and commit tags, so we do not have to roll them out ourselves.
There is one thing that Lerna is not capable of doing automatically though - lockfile updates (and that kills me).
After running lerna version lerna patch (to update the SemVer's PATCH version), we still need to run yarn install (there is no equivalent for npm's --package-lock-only in Yarn) afterward to make sure that the lockfile will reflect that modification. That will make the CI workflow more time-consuming but also more bulletproof. In order to include that step within the lerna version command's execution context, we need to add the following to the scripts section in our top-level package.json:
+ "version": "yarn install && git add yarn.lock"With that addition, Lerna will orchestrate launching the yarn install command to make sure that the lockfile is updated and include new yarn.lock in the commit containing version bumps and correct tags (the script runs right before automatic git commit).
Here is the final simplified (no caching attached) CI workflow for changes detection and commit tagging:
name: Subprojects versioning and tagging
on:
pull_request:
branches:
- master
types: [closed]
jobs:
tag:
name: Generate new versions (patch) and tag the most recent commit
if: ${{ github.event.pull_request.merged == true }}
runs-on: ubuntu-latest
env:
node-version: 14.x
steps:
- uses: actions/checkout@v2
with:
fetch-depth: "0"
- name: Use Node.js ${{ env.node-version }}
uses: actions/setup-node@v1
with:
node-version: ${{ env.node-version }}
- run: git config --global user.email "github-action@noreply.github.com"
- run: git config --global user.name "GitHub Action - versioning"
- name: Generate new version
run: yarn dlx lerna version patch --amend --force-git-tag --yes
- name: Force push
run: git push --atomic --follow-tags --force-with-lease # all or nothing; to make sure we are not going to overwrite most recent commits if multiple PRs are merged at the same timePublishing packages that need to be accessible from outside
Our existing frontend environment is too wide to safely migrate all of the projects to monorepo at once. That may become quite a long process with some cleanup required beforehand. Because some of the projects that we are not migrating in the first iteration still need to reference the shared dependency (shared_lib) that will be now placed in the single @tripleequalsdev/frontend workspace, we need to somehow make it accessible from the monorepo-independent outer scope.
We cannot use the same strategy that we have been using until now. Referencing project's dependencies with git://github.com/tripleequalsdev/shared_lib will not work anymore - the URL will point to the monorepo's root and we do not intend to register a whole multi-project repository as a new dependency just to access a small part of it. Before all of the projects dependant on the shared part are put in the monorepo itself, we are going to publish its respective package into the private GitHub-hosted packages registry. Keeping in mind the fact that each project is versioned independently, synchronizing potential updates to shared libraries should be a piece of cake (just running yarn upgrade @tripleequalsdev/shared_lib --latest will work smoothly). Let's include the publish step in the existing CI pipeline then:
# after force push
- name: Setup .npmrc
uses: actions/setup-node@v1
with:
node-version: 12.x
registry-url: https://npm.pkg.github.com/
scope: '@tripleequalsdev'
- name: Get currently published version of shared library
id: published-lib-version
run: echo "::set-output name=version::$(npm view @tripleequalsdev/shared_lib version)"
env:
NODE_AUTH_TOKEN: ${{ secrets.GITHUB_TOKEN }}
- name: Get version of shared library based on current changes
id: current-lib-version
working-directory: ./packages/shared_lib
run: echo "::set-output name=version::$(node -pe "require('./package.json').version")"
- name: Publish shared library
if: ${{ steps.published-lib-version.outputs.version != steps.current-lib-version.outputs.version }}
working-directory: ./packages/shared_lib
run: npm publish
env:
NODE_AUTH_TOKEN: ${{ secrets.GITHUB_TOKEN }}Warning: we are not going to run lerna publish that is meant to publish new versions for all the workspaces in the monorepo.
One fact needs to be underlined - unless we plan to make any packages publicly available, once we migrate all our frontend projects to the monorepo, we can get rid of the publishing step. Everything will be then managed by Lerna and Yarn workspaces.
TLDR; or The Big Picture
If you feel that you do not need to be familiar with all the low-level details, the wall of text scares you, or you just want to look at the whole CI pipeline from the wider perspective - you are looking in the right paragraph. While I strongly recommend for both Frontend & DevOps folks to read the entire post, the following flowchart may come in handy to understand the big picture without diving deeply into the implementation details:
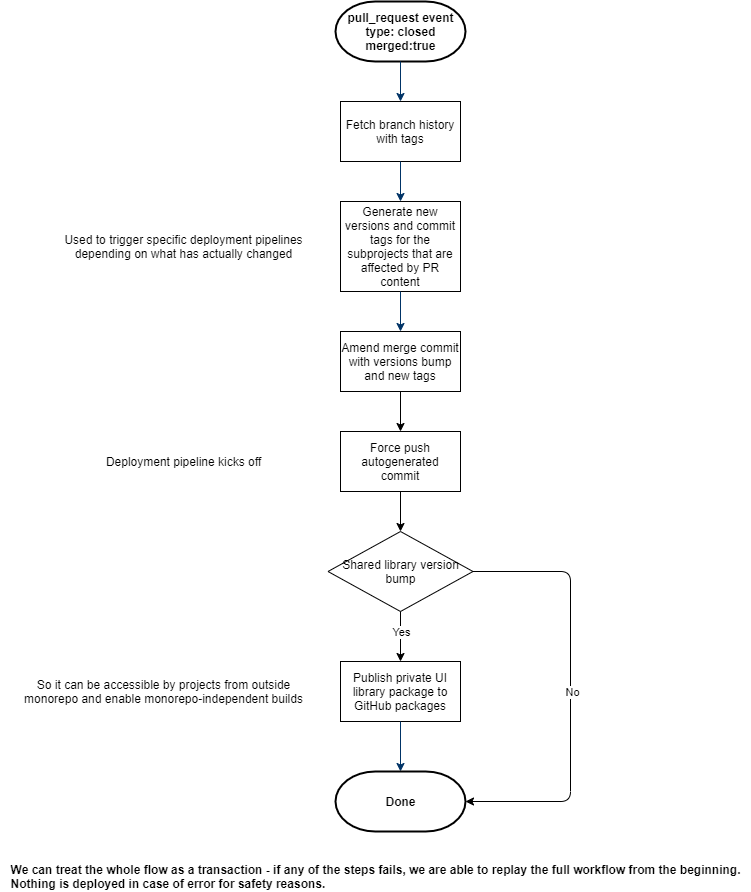
Note on private flag in package.json
If you want to place any of the existing projects in the monorepo, you have to remove private: true from the configuration in its package.json. Even if you do not mean to ever publish the corresponding package (it rather represents a separate deployable entity that the shared library), workspaces marked as private will not be taken into account when executing Lerna commands like e.g. lerna version - thus version tags will never be generated, and the deployment process will not trigger.
Follow-up?
I have found the above high-level design stable and bulletproof enough to serve its needs. What is equally important - I also believe that the approach I have just shown you is scalable and its single bricks can be easily replaced or removed. However, architectural decisions and processes that they try to standardize are not frozen and, just like low-level implementation details, are likely to evolve. NPM team has just announced its official support for workspaces, Rush becomes more popular and well supported, the process requirements may be amended... We all live in the Javascript world; we know how frequently the trends change; we are used to adjusting, growing, and constantly trying new things. While the current solution is a perfect match now, I would be more than happy to experiment with different approaches, get mad at Yarn a few times more, and overcome some new obstacles in the future. If that happens, I will not leave you alone and share my findings with a huge pleasure.
